
By Greg Kamradt
Published 22 Apr 2025
ARC Prize Foundation is a nonprofit committed to serving as the North Star for AGI by building open reasoning benchmarks that highlight the gap between what’s easy for humans and hard for AI. The ARC‑AGI benchmark family is our primary tool to do this. Every major model we evaluate adds new datapoints to the community’s understanding of where the frontier stands and how fast it is moving.
In this post we share the first public look at how OpenAI’s newest o‑series models, o3 and o4‑mini, perform on ARC‑AGI.
Our testing shows:
Despite recent gains, ARC-AGI-2 remains unsolved by the best version of o3, with scores below 3%. To better analyze model behavior and extract meaningful signal, we also evaluate performance on ARC-AGI-1. This earlier version provides a broader range of task difficulty and enables direct comparison with o3-preview results from December 2024.
The ARC-AGI suite of benchmarks are a useful substrate to measure the performance of leading Large Language Models (LLMs) and Large Reasoning Models (LRMs). We've found that ARC-AGI pushes LRMs to their reasoning limits, requiring them to extended their thought processes. ARC-AGI also offers a verifiable domain which helps easily assess the quality of responses.
ARC-AGI-2, introduced in March ‘24, is a next generation benchmark to assess AI reasoning. It builds on ARC-AGI-1 by introducing further symbolic interpretation, multi-compositional rules, and tasks that demand deeper abstraction. ARC-AGI-1 is currently a more sensitive tool, providing a wider range of signal about a model. ARC-AGI-2, however, is primed to measure future, more capable, models as they close the gap between human and AI capabilities.
Using both these datasets we are able to measure the underlying efficiency of intelligence of frontier AI models. Previously, we’ve used ARC-AGI to analyze Deepseek, o3-preview, and other public solutions.
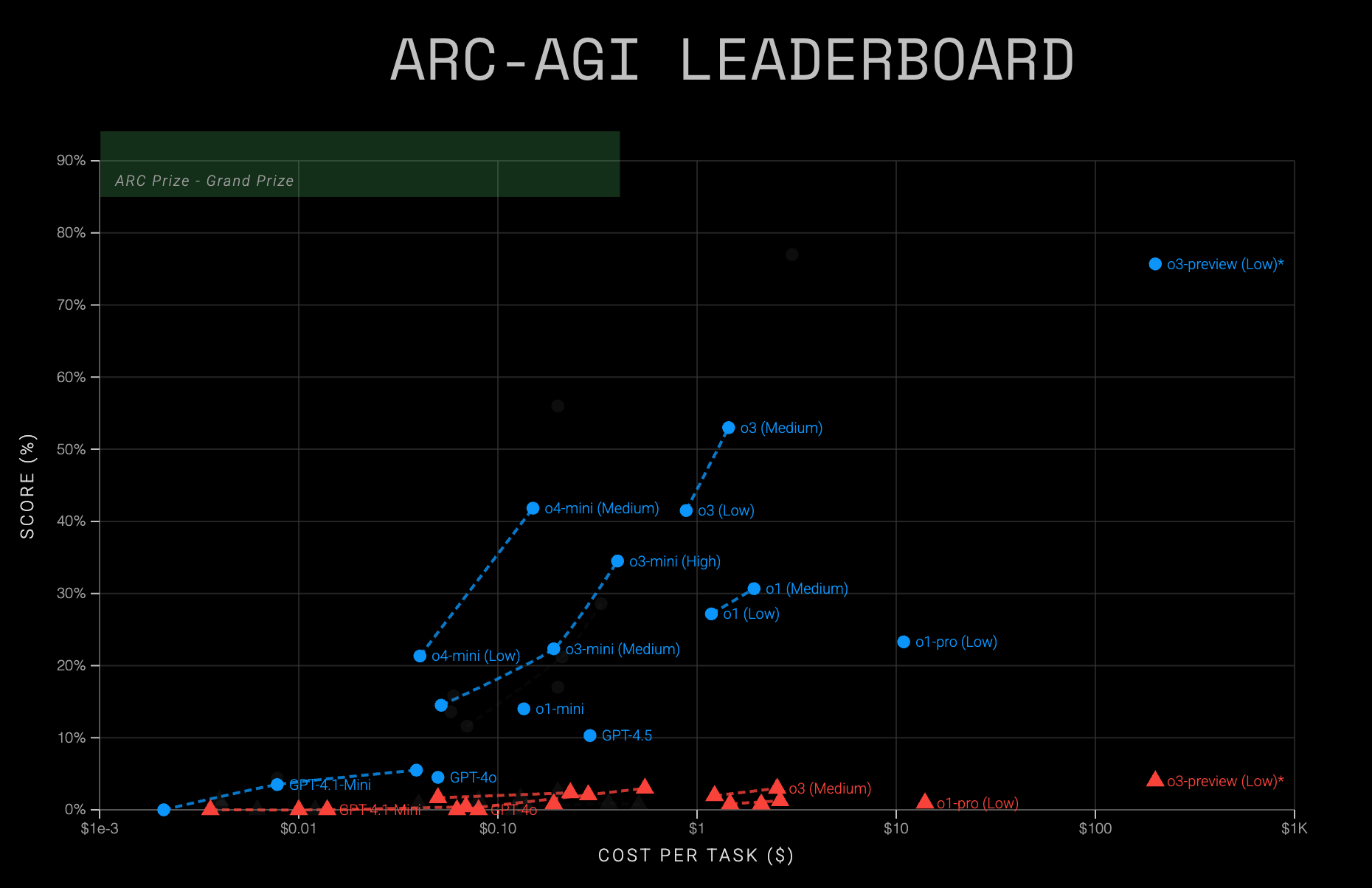
ARC Prize Foundation was invited by OpenAI to join their “12 Days Of OpenAI.” Here, we shared the results of their first o3 model, o3-preview, on ARC-AGI. It set a new high-water mark for test-time compute, applying near-max resources to the ARC-AGI benchmark.
We announced that o3-preview (low compute) scored 76% on ARC-AGI-1 Semi Private Eval set and was eligible for our public leaderboard. When we lifted the compute limits, o3-preview (high compute) scored 88%. This was a clear demonstration of what the model could do with unrestricted test-time resources. Both scores were verified to be state of the art.

Last week OpenAI released 2 new models: o3 and o4-mini. They confirmed that this public o3 model differs from the o3-preview we tested in December 2024.
To evaluate o3 and o4-mini, we tested both models across all available reasoning levels: low, medium, and high. These settings control the depth of the model's reasoning: low favors speed and minimal token usage, while high encourages more exhaustive thought processes.
In total, we ran 2 models (o3 and o4-mini) at 3 reasoning levels (low/med/high) each, tested across 740 tasks from ARC-AGI-1 and ARC-AGI-2 for a total of 4.4K data points. Here’s what we found:
| Model | Reasoning Effort | Semi Private Eval V1 | Semi Private Eval V2 | $/Task (v2) |
|---|---|---|---|---|
| o3 | Low | 41% | 1.9% | $1.22 |
| o3 | Medium* | 53% | 2.9% | $2.52 |
| o3 | High | N/A | ||
| o4-mini | Low | 21% | 1.6% | $0.05 |
| o4-mini | Medium | 42% | 2.3% | $0.23 |
| o4-mini | High | N/A | ||
*Note: o3-medium only returned 93 of 100 test results for ARC-AGI-1 Semi Private Eval. Remaining tasks were scored to be incorrect.
The high reasoning setting did not return enough task completions to support reliable scoring. In most cases, the models failed to respond or timed out, leaving us with incomplete data that falls short of the bar required for leaderboard reporting.
What did return introduces another complication: the first tasks to complete showed higher accuracy than those that came back later, suggesting a non-random subset to analyze. In addition to this, we found that the tasks that didn’t return on high compute tended to be less likely to be solved by lower compute models. Reporting these results would likely inflate the model’s true capabilities and misrepresent performance.
However, in the spirit of transparency, when using “high” reasoning we observed:
To reiterate, the small number of returned tasks and the skewed solve rates make these results unrepresentative and should not be reported on. At best, they reflect an upper bound on performance under high-effort settings. We expect broader testing to bring these scores down as more challenging tasks are attempted.
o3-medium is currently the strongest publicly available model we've tested. o4-mini isn't the most accurate, but it's the most cost-efficient. As always, all responses for public tasks are available on Hugging Face, and you can reproduce these runs using our Model Baseline testing harness. To view these scores in context of other models, see the ARC Prize Leaderboard.
While typical single chain-of-thought (CoT) systems cluster around a ARC-AGI-1 performance ceiling of 30%, o3-medium achieves double that performance. This significant improvement isn't easily explained by simply scaling up earlier base models or standard CoT approaches. One possibility is that o3 employs an enhanced processing model or advanced sampling and optimization techniques that manage to boost accuracy without sacrificing inference speed. However, without explicit architectural insights, this remains speculative.
To try and understand why o3-high failed to respond to certain tasks, we analyzed its token usage, runtime, and performance across other models and ARC-AGI evaluations.
We observed 3 key takeaways:
We noticed that tasks which the model returned sooner had higher accuracy. Those that took longer, either in duration or token usage, were more likely to fail. This signals that the model comes to a conclusion or has higher confidence for easier tasks earlier in the CoT process.
As an aside, this pattern also hints that task difficulty might be inferred from a model's behavior beyond a simple correct/incorrect label.
Below we show the success and token counts over time for tasks responded.

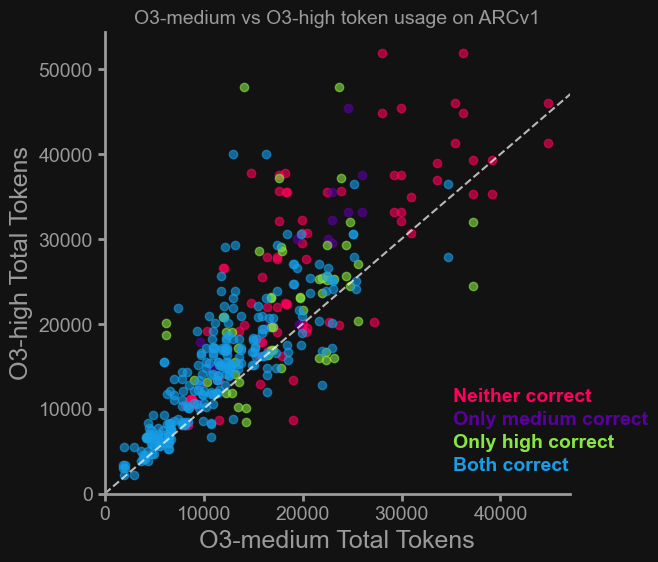
When comparing o3-medium and o3-high on the same tasks, we found that o3-high consistently used more tokens to arrive at the same answers. While this isn’t surprising, it highlights a key tradeoff: On easy tasks, o3-high often offers no accuracy gain but incurs a higher cost. If you’re cost-sensitive, evaluate if you really need to use high reasoning, medium may be the better default. However, if maximizing accuracy is critical and cost is less of a concern, high reasoning still has its place.
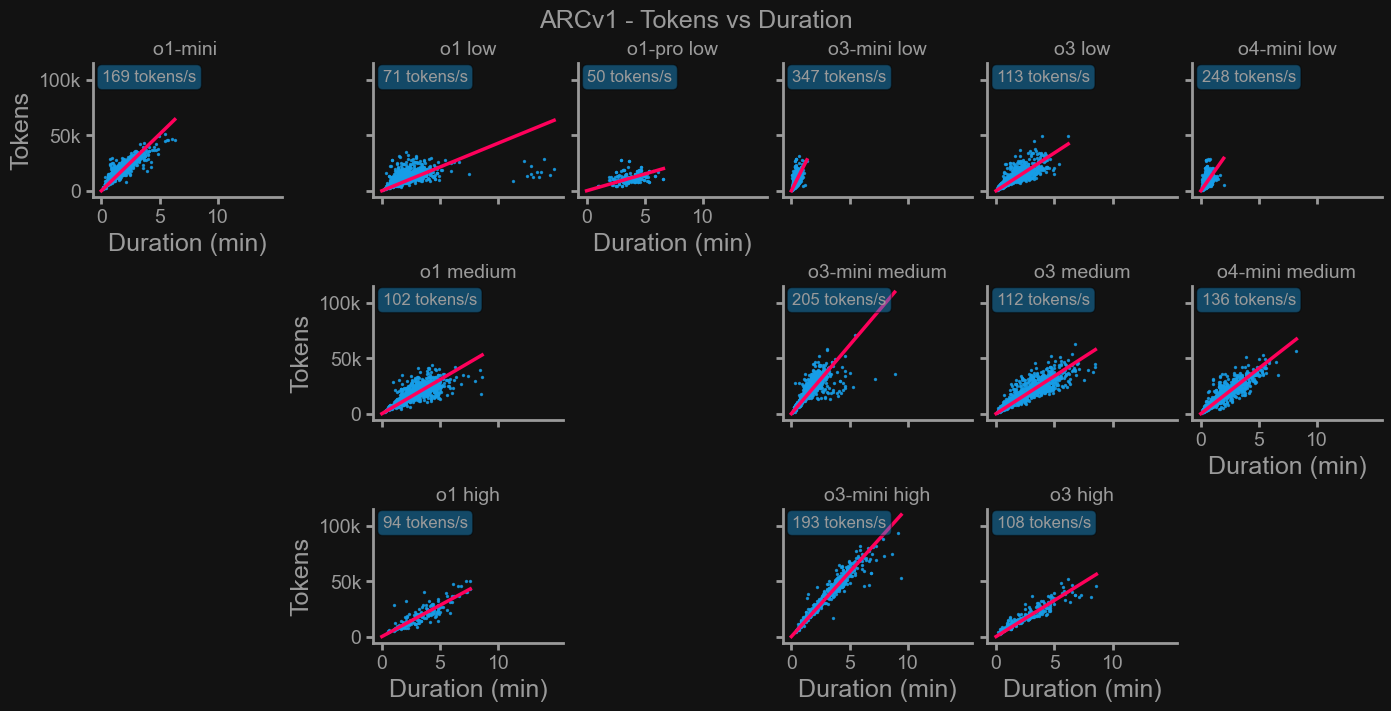
Next, we looked at tokens-per-second for each task across o-series models. We found that o3-mini-low and o4-mini-low had higher throughput (tok/s) than their medium and high counterparts. This indicates a likely algorithmic differences in mini models, though its exact cause remains unclear.
OpenAI’s newest o‑series releases push the boundaries of reasoning models, they keep the frontier moving and give the community visibility into what today’s models can (and still can’t) do. ARC‑AGI exists to serve as the guidepost that shows how far we’ve come.
As these systems grow more powerful, efficiency (how fast, at what cost, and using how few tokens a model solves problems) becomes the key differentiator.
If you’re excited to contribute frontier model analysis or help fund transparent, public benchmarks, we’d love to talk. Reach us at team@arcprize.com or consider supporting the ARC Prize Foundation today.
Thank you to Henry Pinkard for leading data analysis, Mike Knoop for a review of an early draft and OpenAI for credits to perform additional testing.